
El 4 de octubre de 2021, algo que nadie jamás se hubiera imaginado estaba pasando: se habían caído TODOS los servicios de Facebook. Sobre las 16 horas UTC, más de 3 billones de personas quedaron «incomunicadas» al no poder acceder a sus redes habituales. El apagón duró casi seis horas, y pese a provocar multitud de teorías conspiranóicas, todo se debió a un cúmulo de sucesos que provocó la desconexión «desde dentro» de este gigante de Internet.
A continuación la explicación detallada de los hechos en base a toda la documentación que he podido recabar, intentando utilizar un lenguaje lo más «humano» posible. En ocasiones tendré que usar terminologías concretas, pido disculpas a quienes se pierdan en algunos conceptos , pero creo que el mensaje general quedará claro. Si necesitas alguna aclaración adicional, no dudes en contactarme por Twitter a @rafamerino,
Si eres un/a «gurusete» de las maquinitas y algo no está bien explicado, entiende que lo he simplificado todo para el entendimiento general, pero estaré encantado de leer tus aclaraciones en los comentarios.
1.- El backbone
Conforme crecen los servicios de Facebook, crece la comunicación interna entre sus datacenters. Este crecimiento de tráfico entre máquinas es muchísimo más alto que el que generan los propios usuarios. Esto suponía un problema para la red social, ya que la gran cantidad de tráfico que movían sus servidores para comunicarse estaba afectando a la velocidad a la que cargaban contenido a los usuarios:
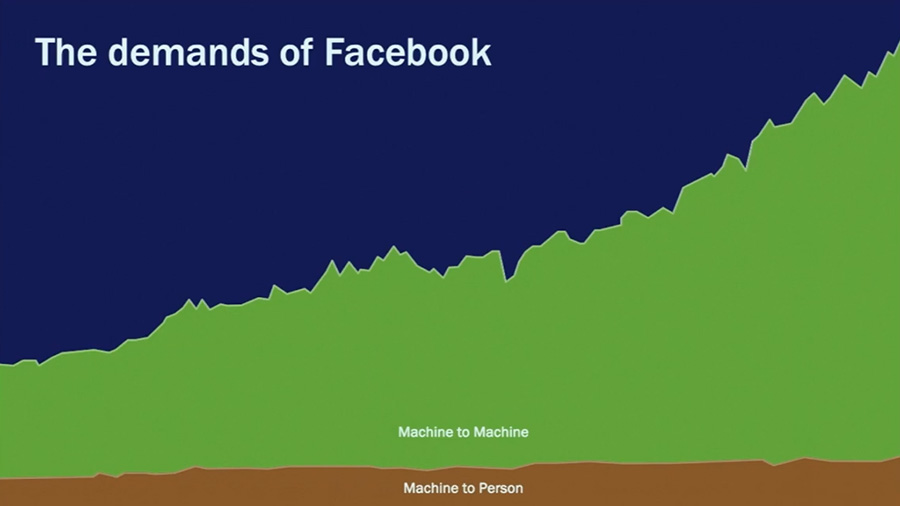
Es por esto que Facebook decidió hace años crear una red «interna» (troncal) que funciona también a través de Internet, pero por otros canales distintos a los del tráfico que va hacia «afuera» de sus servidores (es decir, hacia nosotros los usuarios) ganando rapidez de comunicación «interna» sin saturar el tráfico «externo».
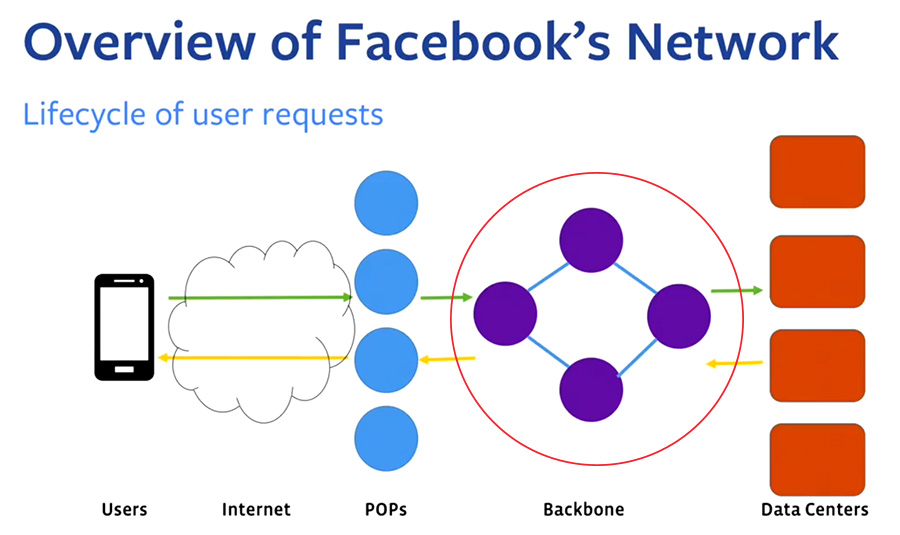
En 2017, el Backbone evolucionó un paso más y pasó a denominarse Express Backbone (EBB), el cual permite mucha más flexibilidad, control y automatización a la hora de implementar actualizaciones, cambios (físicos) de máquinas o reconfiguraciones. Inicialmente, utilizaban una combinación de IGP y «full mesh iBGP«, pero posteriormente reemplazaron el IGP con un desarrollo propio específico para esta tarea, llamado Open/R, que les daba mayor control y mejor tolerancia a errores.
2.- Robotron
La cantidad de datacenters y servidores que utiliza Facebook hace inviable poder trabajar con un solo proveedor de máquinas, por lo que a la hora de configurar nuevas instalaciones (o reconfigurar viejas), los ingenieros de Facebook tenían que cargar manualmente plantillas de configuración de enrutamiento de distintos fabricantes. Para evitar esto, diseñaron una aplicación/script llamado Robotron, que permite configurar de manera uniforme todos los servidores (tanto a nivel de conectividad como de operaciones) independientemente del fabricante o del hardware sobre el que estuvieran trabajando.
Según cuenta Facebook, esta aplicación dispone de un sistema de prevención de errores para evitar este tipo de comandos erróneos, pero un fallo (bug) en el módulo que audita los comandos resultó en que se enviara la orden sin que nada pudiera prevenir la catástrofe. La orden concreta, indican sus ingenieros, era para evaluar la disponibilidad de su «backbone» a nivel global (una especie de «foto» de la situación de sus sistemas internos).
En mi humilde opinión, dudo bastante que un comando de «status» provoque este tipo de catástrofe, básicamente porque una orden de consulta de situación no te elimina la conectividad a nivel interno. Estás queriendo conocer algo, no borrarlo. No me cuadra la explicación oficial.
Leyendo documentación de FB sobre este tema y viendo el protocolo que siguen para actualizar y reconfigurar máquinas, MI HIPÓTESIS es que quisieron lanzar un «drain» (algo así como una «desconfiguración» de máquinas) sobre el EBB de algún datacenter para hacer alguna prueba como las de estress que hicieron durante Covid, y algo salió mal… No conozco cómo funciona Robotron y no está documentado públicamente, pero tal vez pusieron un asterisco « * » a la hora de lanzar el comando (como un comodín, que sería algo así como «seleccionar todo«) en lugar de limitar el comando de desactivación para un datacenter/rack concreto.
3.- La desconexión desde dentro
La infraestructura de Facebook es tan grande que tienen varias capas de protección ante fallos, lo que permite que el tráfico de los usuarios no se vea afectado incluso si cae un datacenter entero. Una de estas protecciones es que sus servidores DNS, que son los únicos que conocen dónde redirigir exactamente el tráfico externo a sus servidores internos, en caso de detectar que hay un fallo de conexión de un EBB concreto, borra a esa conexión interna de la tabla de resoluciones externas (los famosos BGP) para evitar dar errores de carga de página a los usuarios, redirigiendo el tráfico a otro datacenter/servidor.
Si todo funciona correctamente, una solicitud de un usuario llega al DNS de Facebook, el cual redirige la petición al datacenter más cercano. Entonces, el servidor envía a través de los famosos BGP la «respuesta» (la página, el audio de WhatsApp, lo que sea) al usuario.
Si algo falla, el DNS desactiva esa ruta del BGP ya que detecta que el datacenter no está operativo, enviando esas solicitudes de tráfico a otro servidor. Al lanzar el comando de Robotron, TODOS los datacenters quedaron inoperativos internamente, por lo que los servidores DNS borraron TODAS las rutas BGP, ya que para eso estaban programados. Evidentemente, cuando programaron este sistema de re-enrutado, jamás se imaginarían que todos los datacenters caerían a la vez…
4.- El reinicio, a veces no es tan sencillo
El borrado de BGPs fue tan rápido y global que deshabilitó el acceso a poder reconfigurar la red, incluyendo las herramientas internas de trabajo, de desarrollo e incluso de comunicación que utiliza Facebook en su día a día (servidores VPN, workplace, su email interno, todo!). Esto supuso tener que desplazarse físicamente a un grupo de ingenieros con los conocimientos necesarios, para restaurar el backbone a mano.

Otro problema que surgió es que para poder acceder hasta el terminal de una máquina concreta en un datacenter, debes superar varias medidas de seguridad tanto físicas como digitales. Esto hizo perder mucho tiempo a los ingenieros hasta que finalmente pudieron ponerse con la tarea. Además, reiniciar semejante volumen de red e infraestructuras, conlleva unos efectos secundarios tan complejos que no basta con meter de nuevo la plantilla en la máquina y aplicar los cambios.
5.- Recuperando la conectividad
Levantar de nuevo toda su infraestructura requería una coordinación a nivel global muy bien preparada. La «suerte» para FB es que, no hace mucho, habían simulado la recuperación de un datacenter entero y sabían perfectamente cómo realizar el proceso de manera sincronizada. De haber levantado la conectividad sin más, habrían provocado picos de consumo de electricidad tan elevados que habrían tumbado de nuevo el servicio.
Para que nos hagamos una idea, algunos datacenters que se fueron «despertando» de la caída de una manera controlada, reportaron descensos de electricidad de decenas de megavatios, debido a tantas máquinas recuperando conectividad y volviendo a trabajar al mismo tiempo.

En resumen, la que probablemente sea la mayor caída de servicios de Intenet en mucho tiempo, fue provocada por el cúmulo de un error humano, un error de programación en un script de mantenimiento y un sistema de protección DNS que hizo lo que tenía que hacer.
Descargo de responsabilidad: Toda la información publicada, incluyendo imágenes, ha sido obtenida de la documentación pública oficial de Facebook. Esto es un análisis y opinión personal de lo ocurrido y no se trata de información confirmada ni denegada por parte de Facebook. No tengo relación alguna con Facebook o sus trabajadores, más allá de tener un perfil de usuario en dicha red social.
«𝙉𝙤 𝙡𝙤 𝙨𝙚́, 𝙥𝙚𝙧𝙤 𝙫𝙤𝙮 𝙖 𝙙𝙤𝙘𝙪𝙢𝙚𝙣𝙩𝙖𝙧𝙢𝙚»
— Rafa Merino (@rafamerino) 7 de octubre de 2021
👆 La actitud de una persona con éxito
Fuentes: